[AWS] Amazon Aurora 이해
AWS에서 제공하는 Amazon Aurora를 이해해보자.
- 1. Amazon Aurora 개요
- 2. Amazon Aurora 아키텍쳐
- 3. Amazon Aurora 특징
- 4. Aurora Global Database
- 5. 병렬 쿼리
- 6. Aurora 백업
- 7. Aurora 데이터베이스 클로닝
- 8. 역추적(Backtrack)
1. Amazon Aurora 개요
Amazon Aurora는 고성능 상용 데이터베이스의 성능과 가용성에 오픈 소스 데이터베이스의 간편성과 비용 효율성을 결합하여 클라우드를 위해 구축된 MySQL 및 PostgreSQL 호환 관계형 데이터베이스이다.
Amazon Aurora는 표준 MySQL 데이터베이스보다 최대 5배 빠르고 표준 PostgreSQL 데이터베이스보다 3배 빠르다.
또한 1/10의 비용으로 상용 데이터베이스의 보안, 가용성 및 안전성을 제공한다.
하드웨어 프로비저닝, 데이터베이스 설정, 패치 및 백업과 같은 시간 소모적인 관리 작업을 자동화하는 Amazon Relational Database Service(RDS)에서 Amazon Aurora의 모든 것을 관리한다.
기존의 RDS와는 다른 아키텍쳐를 가지고 있기 때문에, 클라우드 환경에 최적화된 RDBMS라고 볼 수 있다.
2. Amazon Aurora 아키텍쳐
Aurora의 아키텍쳐는 Single-Master와 Multi-Master로 나뉜다.
I. Single-Master
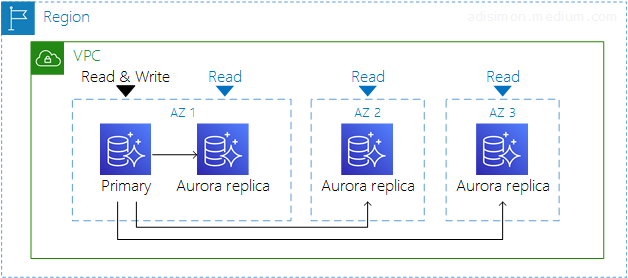
Single-Master는 여러 가용 영역에 걸쳐서 Storage Cluster(=Cluster Volume, 저장 공간)이 분리되어있으며, 그 위에 Master 인스턴스(=Writer 인스턴스, 쓰기, 읽기를 담당)와 Replica 인스턴스(= Reader 인스턴스, 읽기만 가능)이 올려져 있는 형태이다.
쓰기의 경우 Master 인스턴스만이 사용자로부터 요청을 받아 Storage Cluster에 데이터를 저장할 수 있다.
읽기의 경우 Master 인스턴스와 Replica 인스턴스들이 Storage CLuster로부터 값을 받아와 사용자에게 전달한다.
Replica 인스턴스는 최대 15개까지 생성할 수 있다. Async 복제가 가능하다. 하나의 리전안에 생성이 가능하다. 한 대의 Master 인스턴스가 다운될 경우 자동으로 Replica 중 하나가 Master로 승격(Failover)된다.
이렇게 읽기/쓰기와 저장을 분리했기 때문에 인스턴스 생성과 전환을 매우 빠르게 할 수 있다.
이 뿐만 아니라 고가용성을 확보하기 위해 스토리지 노드끼리 백업이나 싱크를 맞추는 등 Replication 작업 없이도 설계단에서 스토리지를 공유하기 때문에 이미 고가용성을 확보한 상태이다.
II. Multi-Master
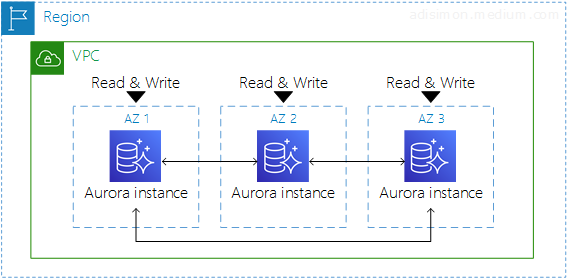
Multi-Master는 Single Master와 다르게 읽기/쓰기를 담당하는 Master 인스턴스가 여러개이다.
이러한 Master 인스턴스는 최대 4개까지 생성할 수 있다.
각 인스턴스는 서로의 정지/재부팅/삭제 등에 영향을 받지 않으며 독립적이다. 이 경우 지속적인 가용성, 부하 분산, 샤딩(Sharding), 멀티테넌트(Multitenant)에서의 유리함이 있다.
대부분의 경우 Single-Master를 사용한다.
왜냐하면 Multi-Master도 나름의 장점이 있지만, Multi-Master를 사용할 경우 Aurora의 몇 가지 기능을 사용하지 못하게 되기 때문이다.
3. Amazon Aurora 특징
I. 용량의 자동 증감
RDS의 경우 EBS를 기반으로 했기 때문에 미리 저장공간을 확보해서 EBS를 생성해야 했지만, Aurora의 경우 10GB부터 시작하여 10GB 단위로 최대 128TB까지 자동으로 용량이 늘어난다.
이는 RDS와 달리 읽기/쓰기 인스턴스를 스토리지와 분리시켰기 때문에 가능한 것이다.
II. 데이터 분산 저장
최소 3개 이상의 AZ X 각 AZ마다 2개의 데이터 복제본 저장 = 최소 6개의 복제본
즉 3개 이상의 복제본이 손상되기 전에는 쓰기 능력이 유지된다.
즉 4개 이상의 복제본이 손상되기 전에는 읽기 능력이 유지된다.
또한 복제본이 손상되더라도 클러스터가 지속적으로 손실된 부분을 검사 후 복구한다.
Quorum 모델을 사용하여 읽기/쓰기를 적용한다.
4. Aurora Global Database
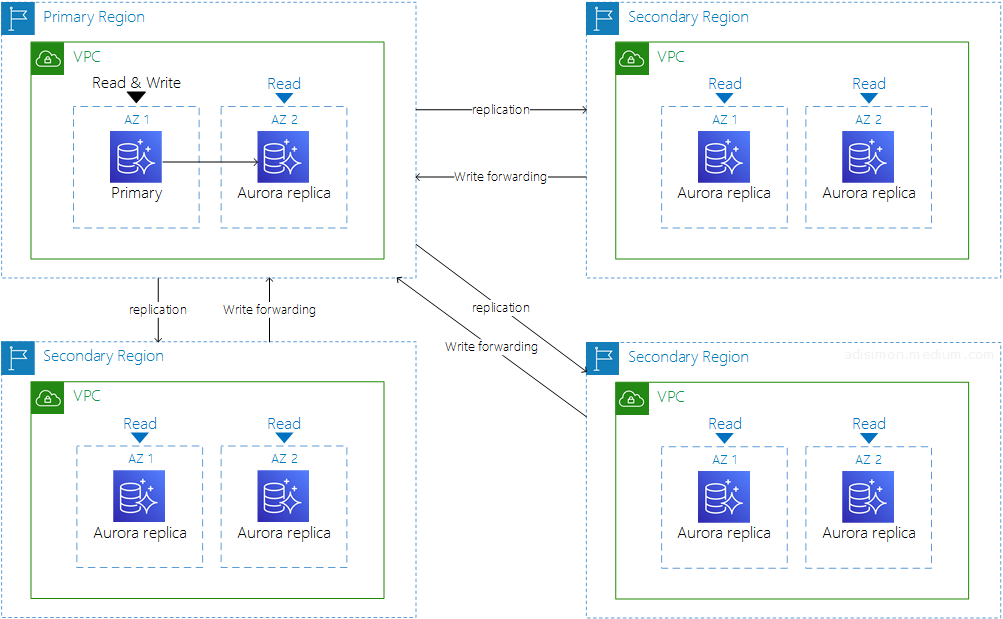
Aurora Global Database는 전 세계의 모든 리전에서 1초내의 지연시간으로 데이터 액세스가 가능한 서비스이다.
Aurora가 위치한 리전에서 다른 리전으로 데이터를 자동 복제한다.
RDS의 Cross Region Replication과 유사하다.
재해 복구 용도로도 활용 가능하다.
유사시 보조 리전중 하나를 승격하여 메인으로 활용한다.
1초의 RPO(Recovery Point Objective, 복구 목표 지점) - 1초 전까지의 데이터는 안전이 보장된다.
1분 미만의 RTO(Recovery Time Objective, 복구 목표 시간) - 1분 내에 복구가 보장된다.
보조 리전에는 총 16개의 Read 전용 노드(Replica 인스턴스) 생성이 가능하다(메인 리전에서는 15개).
5. 병렬 쿼리
다수의 읽기 노드를 통해 쿼리를 병렬로 처리하는 모드이다.
빠르고 부하 분산의 효과가 있다.
대규모 쿼리의 경우 병렬 쿼리를 통해 소요되는 시간을 대폭 줄일 수 있다.
MySQL 5.6/5.7에서만 지원하며, 몇몇 낮은 인스턴스에서는 지원하지 않는다.
6. Aurora 백업
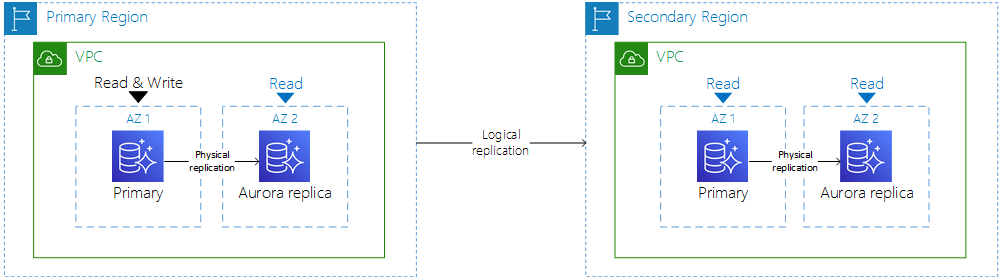
읽기 전용 인스턴스(Read Replica)를 지원한다.
MySQL DB의 Binary log 복제(Binlog)이다.
다른 리전에만 생성이 가능하다(메인 리전에서는 백업할 필요가 없음).
RDS와 마찬가지로 자동/수동 백업이 가능하다.
자동 백업의 경우 1~35일 동안 보관한다(S3에 보관).
수동 백업(스냅샷)이 가능하다.
백업 데이터를 복원할 경우 다른 데이터베이스를 생성한다.
원본 데이터베이스는 그대로 두고, 새로 데이터베이스를 생성해서 복원한다는 뜻이다.
7. Aurora 데이터베이스 클로닝
기존의 데이터베이스에서 새로운 데이터베이스를 복제한다.
스냅샷을 통해 새로운 데이터베이스를 생성하는 것 보다 빠르고 저렴하다.
Copy-On-Write 프로토콜을 사용한다.
Copy-On-Write 프로토콜
Aurora에서는 모든 데이터를 page단위로 저장한다.
데이터베이스 클로닝을 할 때 이 page들을 복제하는 것이 아니라, 먼저 빈 데이터베이스(클론 데이터베이스)부터 생성한다.
이 데이터베이스는 원본 데이터베이스의 page들을 참조하고 있다.
이 상태에서 원본 데이터베이스의 데이터 어떠한 변화(DELETE, UPDATE 등의 Write)가 생기면 Aurora에서 변화된 데이터가 들어있는 페이지(이하 A 페이지)를 원본 데이터베이스와 연결을 끊고, 새로운 A 페이지를 만들어서 변화를 적용하고 연결한다.
이 때 클론 데이터베이스는 새로운 A 페이지를 참조하는 것이 아닌 원래 상태 그대로 원본 A 페이지를 참조하고 있다.
클론 데이터베이스에 어떠한 변화(Write)가 생겼을 경우, 참조하고 있던 데이터가 들어있는 페이지(이하 B 페이지)와의 연결을 끊고 새로운 B 페이지를 만들어 변화를 적용하고 연결한다.
Copy-On-Write 프로토콜의 장점은 클로닝 즉시 새로 데이터들을 복제해서 만드는 것이 아니라, 변화가 생겼을 때만 새로 만들기 때문에 스냅샷을 통해 데이터베이스를 새로 만드는 것 보다 훨씬 빠르다.
또한 클러스터가 삭제되더라도(원본 데이터베이스와 페이지가 삭제되더라도) 내부적으로 클론 클러스터가 제대로 작동할 수 있도록 한다.
8. 역추적(Backtrack)
데이터베이스 클로닝처럼 새로운 DB를 만드는 것이 아닌, 기존의 DB를 특정 시점으로 되돌리는 것이다.
따라서 DB 관리의 실수를 쉽게 만회할 수 있다(예 : WHERE 없이 사용한 DELETE).
새로운 DB를 생성하는 것보다 훨씬 빠르다.
변경된 부분만 반영하면 되기 때문이다.
앞 뒤로 시점을 이동할 수 있기 때문에 원하는 지점을 빠르게 찾을 수 있다.
MySQL 환경에서만 가능하다.
또한 Aurora 생성시 Backtrack을 설정한 DB만 Backtrack이 가능하다. 처음에 설정하지 못했을 경우, 스냅샷을 복구하거나 Clone을 통해 새로운 DB를 만들어 기능을 활성화 할 수 있다. Multi-Master 상태에서는 Backtrack이 불가능하다.
Backtrack Window
BackTrack 윈도우에는 Target Backtrack Window와 Actual Backtrack Window가 있다.
- Target Backtrack Window
- 어느 시점만큼 DB를 되돌리기 위한 데이터를 저장할 것인지 정함
- 지정된 시점 이전으로는 Backtrack이 불가능
- Actual Backtrack Window
- 실제로 시간을 어느만큼 되돌릴지 정함
- Target Backtrack Window 시점보다 이전으로 되돌릴 수는 없음
Backtrack을 활성화하면 시간당 DB의 변화를 저장한다.
저장된 용량만큼 비용을 지불해야 하고, DB의 변화가 많을수록 많은 로그가 쌓이게 되므로 비용이 올라간다.
DB 로그가 너무 많아서 Target Backtrack Window(설정값)만큼의 시간을 다 저장하지 못 할 경우(요금 제한 등의 이유로 인해), Target Backtrack Window(설정값)보다 Actual Backtrack Window 가능 시간이 적어지게 된다.
이 때 AWS에서 알림이 온다.
즉 DB의 변화가 너무 많아 로그 용량이 너무 커질 경우, 내가 설정한 Target Backtrack Window 설정값이 보장하는 시간을 만족시키지 못하게 되므로 알림이 오게 된다.
